Архитектура матричного коммутатора
Архитектура коммутатора реализована с помощью аппаратной сети, которая осуществляет индивидуальные соединения типа точка-точка: процессора с процессором, процессора с основной памятью и процессора с магистралью данных ввода/вывода. Эта сеть работает совместно с разделяемой адресной шиной. Такой сбалансированный подход позволяет использовать лучшие свойства каждого из этих методов организации соединений.
Разделяемая адресная шина упрощает реализацию наблюдения (snooping)за адресами, что необходимо для аппаратной поддержки когерентности памяти. Адресные транзакции конвейеризованы, выполняются асинхронно . расщеплено по отношению к пересылкам данных и требуют относительно небольшой полосы пропускания, гарантируя, что этот ресурс никогда не войдет в состояние насыщения.
Организация пересылок данных требует больше внимания, поскольку уровень трафика и время занятости ресурсов физического межсоединения здесь существенно выше, чем это требуется для пересылки адресной информации. Операция пересылки адреса представляет собой одиночную пересылку, в то время как операция пересылки данных должна удовлетворять требованию многобайтной пересылки в соответствии с размером строки кэша. При реализации отдельных магистралей данных появляется ряд дополнительных возможностей, которые обеспечивают:
- максимальную скорость передачи данных посредством соединений точка-точка на более высоких тактовых частотах;
- параллельную пересылку данных посредством организации выделенного пути для каждого соединения;
- разделение адресных транзакций и транзакций данных.
Поэтому архитектуру PowerScale можно назвать многопоточной аппаратной архитектурой (multi-threaded hardware architecture) с возможностями параллельных операций. На рис. 3 показаны основные режимы и операции, выполняемые матричным коммутатором.
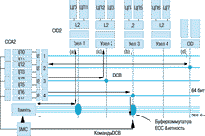
Рисунок 3.
Матричный коммутатор.
Режим обращения к памяти . Memory mode: (a). Процессорный узел или узел в/в коммутируется с массивом памяти (MA). Такое соединение используется для организации операций чтения памяти или записи в память.
Режим вмешательства (чтение): (b). Читающий узел коммутируется с другим, вмешивающимся узлом и шиной данных MA. Этот режим используется когда при выполнении операции чтения строки от механизма наблюдения за когерентным состоянием памяти поступает ответ, что данная строка находится в кэш-памяти другого узла и модифицирована. В этом случае данные, извлекаемые из строки кэша владельца, подаются читающему узлу и одновременно записываются в MA. Если читающий и вмешивающийся ЦП находятся внутри одного и того же узла, то данные заворачиваются назад на уровне узла и одновременно записываются в память.
Режим вмешательства (чтение с намерением модификации . RWITM):(c). Процессорный узел или узел в/в (читающий узел) коммутируется с другим процессорным узлом или узлом в/в. Этот режим используется тогда, когда при выполнении операции RWITM от механизма наблюдения поступает ответ, что данная строка находится в кэш-памяти другого узла и модифицирована. В этом случае данные, извлекаемые из строки кэша владельца, подаются только читающему узлу и не записываются в память.
Режим программируемого ввода/вывода (PIO): (d). Процессорный узел коммутируется с узлом в/в. Это случай операций PIO, при котором обмен данными происходит только между процессором и узлом в/в.
Режим в/в с отображением в памяти (memory mapped). Главный узел коммутируется с узлами в/в (подчиненными узлами), вовлеченными в транзакцию. Это случай операций с памятью.